Transformers

![]()
The before times, a quick recap
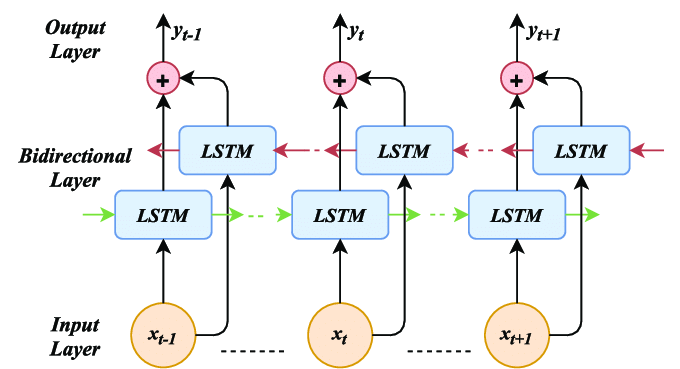
- RNNs, LSTMs, and GRUs for modelling sequential data
- Introduced for NLP and then used in other domains
- Relies on sequential nature of data to extract meangings
- Requires purposeful and meanginful embeddings
Persistant issues

- Long sequences presented challenges - vanishing/exploding gradients
- Bidirectionality helped, but increased complexity and not suitable for every task
- Hard to parallelise, slow to train, tends to overfit
- Black box interpretability, lots of internal components
Transformers fundamentals
![]()
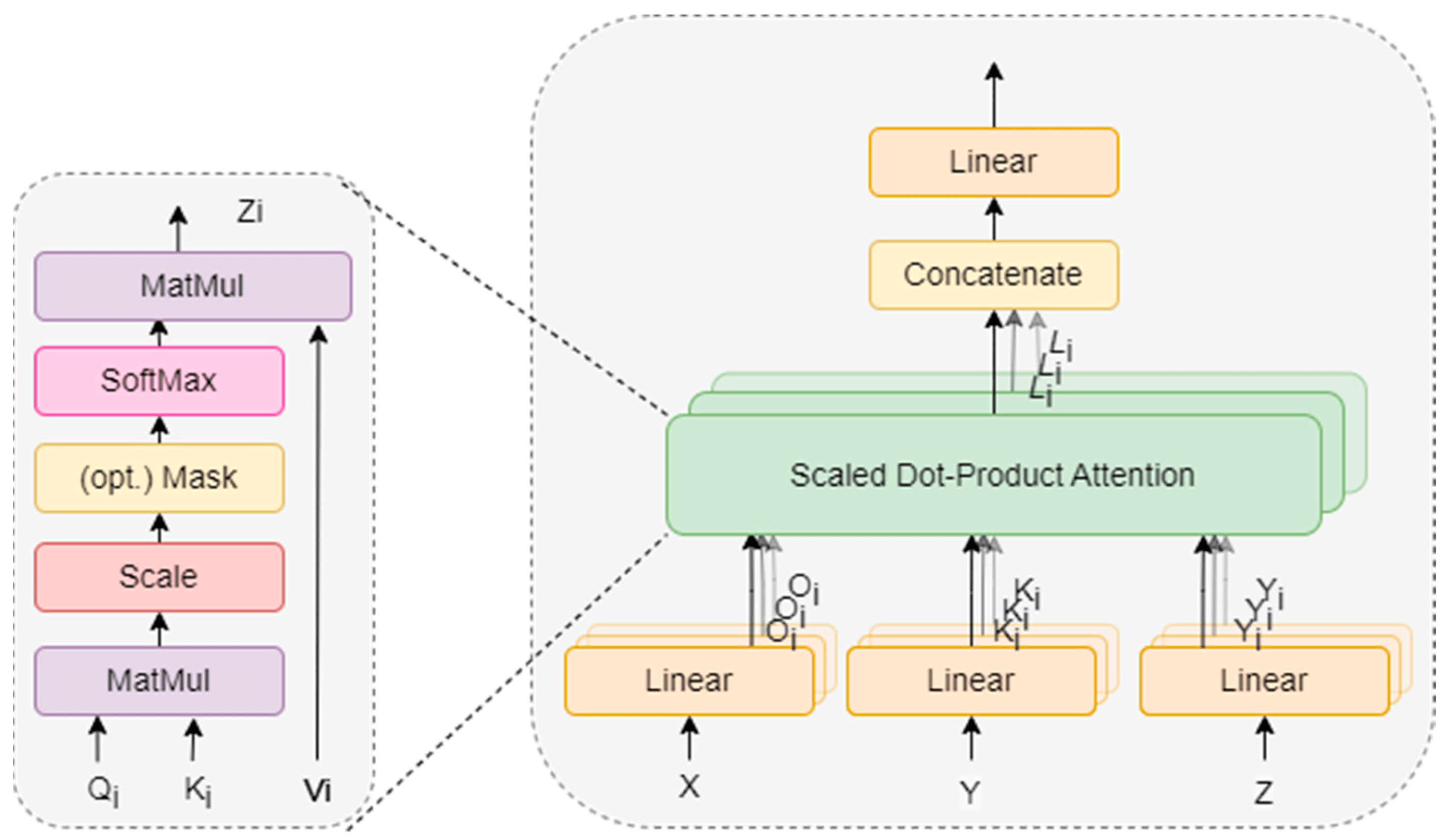
Two-part network with an encoder to generate representations of the embdedded data, and a decoder to generate the output sequence
Combines:
- Input embeddings
- Positional encoding
- Multi-head self attention
- Layer normalisation and residual connections
- Feed-forward neural networks
- Stacked layers
- Output layer
Does not process inputs sequentially, so training and inference can be done in parallel
This allows for much longer sequences to be processed without fear of degradation
A quick graphical overview
Developments beyond the original transformer
A zoom in: Text-video embedding in a challenging data space
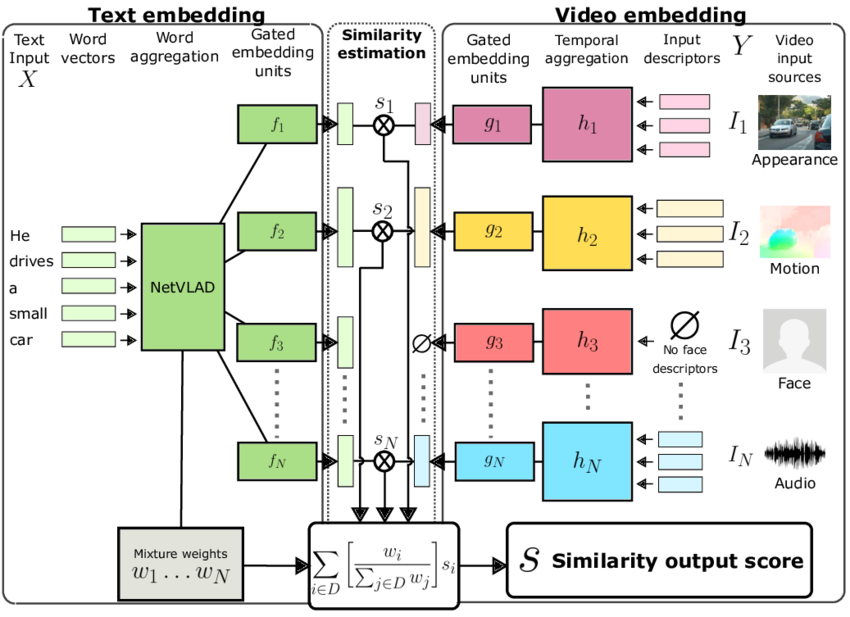
Paper proposes a Mixture-of-Embedding-Experts (MEE) model that learns a joint text-video embedding.
Handles heterogenous data and missing input modalities during training and testing.
- Model learns to combine multiple input streams of video descriptors and textual input to compute a similarity score
- Handles appearance, motion, sound,
facial descriptors - Gated embedding module to transform the
input features into a new feature space - Videos augmented with COCO images
- Outperforms SATA on multiple datasets
A zoom in: Token Merging (ToMe)
![]()
Vision Transformers (ViTs) are specifically designed for computer vision tasks.
Key components include:
- Patch embedding - fixed-size patches linearly embdeed into a vector
- Positional embeddings - added to each patch to preserve spatial information
- Transformer encoder - Fed into standard encoder, no decoder interaction
- Classification token - learnt token added to the sequence with the encoder output used as input to the final classification head
ViTs are more efficient than CNNs, especially for larger images. Self-attention captures global information and contextual relationships between patches. Higher capacity than CNNs
A zoom in: Token Merging (ToMe) continued
Paper looks at improving throughput of ViT models without retraining, by gradually combining similar tokens using a fast and lightweight matching algorithm. Evaluated on ImageNet-1K and Kinetics-400 datasets.
- 98% of tokens are gradually removed, reducing computational cost
- Works across images, videos, and audio
- Achieves speedup of up to 3x without sacrifing accuracy
- Outpeforms prior token pruning methods