Weak Supervision
Some intuition
- Weak supervision: The usage of high-level or noisy data sources as a form of input into ML models
- The goal is to generate large datasets more rapidly than is capable through manual annotation
- Useful for when problems can be solved via lots of imperfect labels rather than small amounts of perfect labels
- Analysing when, how, and where different labelling functions agree or disagree with eah other to determine when and how much to trust them

- Data sources range from high to low quality
- Example domains: Time series analysis, video and image classification, text and document classification
The case of active learning
Active learning can be used as a form of SSL
Learner machine iteratively selects data it is most uncertain about / are the most informative
Human oracle labels this smaller subset of data, reducing overall amount of data to be manually labelled
May introduce bias to the data that the machine learns from
Let’s have a go at it!
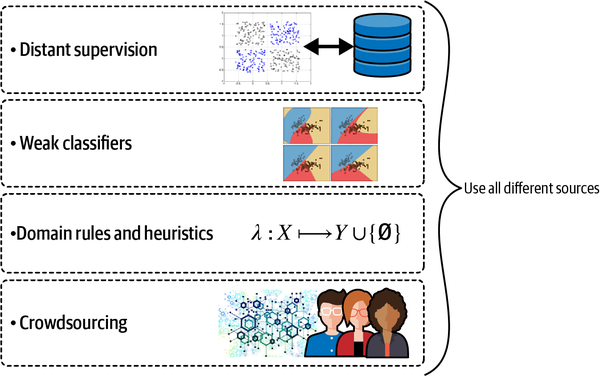

- Crowdsourcing
- Automatic labelling functions
- Mixed level of expert annotation
Data programming continued
Even in their simple application of a binary classification task, a complex set of dependencies can be modelling between the labelling functions
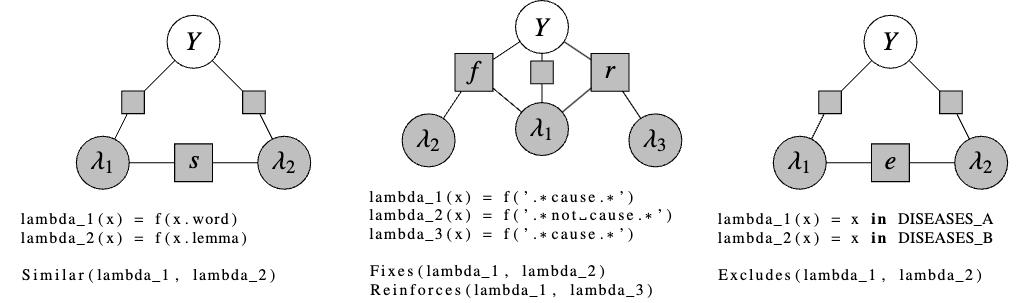
User-defined dependency graphs can be used to help model relationships, but this can become unwieldy
Data programming performance relies on the quality of labelling functions and the specific task and nature of the weak supervision sources involved
Snorkel AI
- First system to employ data programming, allowing users to write labelling functions which are noisy and potentially conflicting
- Denoises labels using a generative model that trains a discriminative model (DNN) on probabilistic labels
- Key innovation is the combining of multiple weak supervision sources with no ground truth
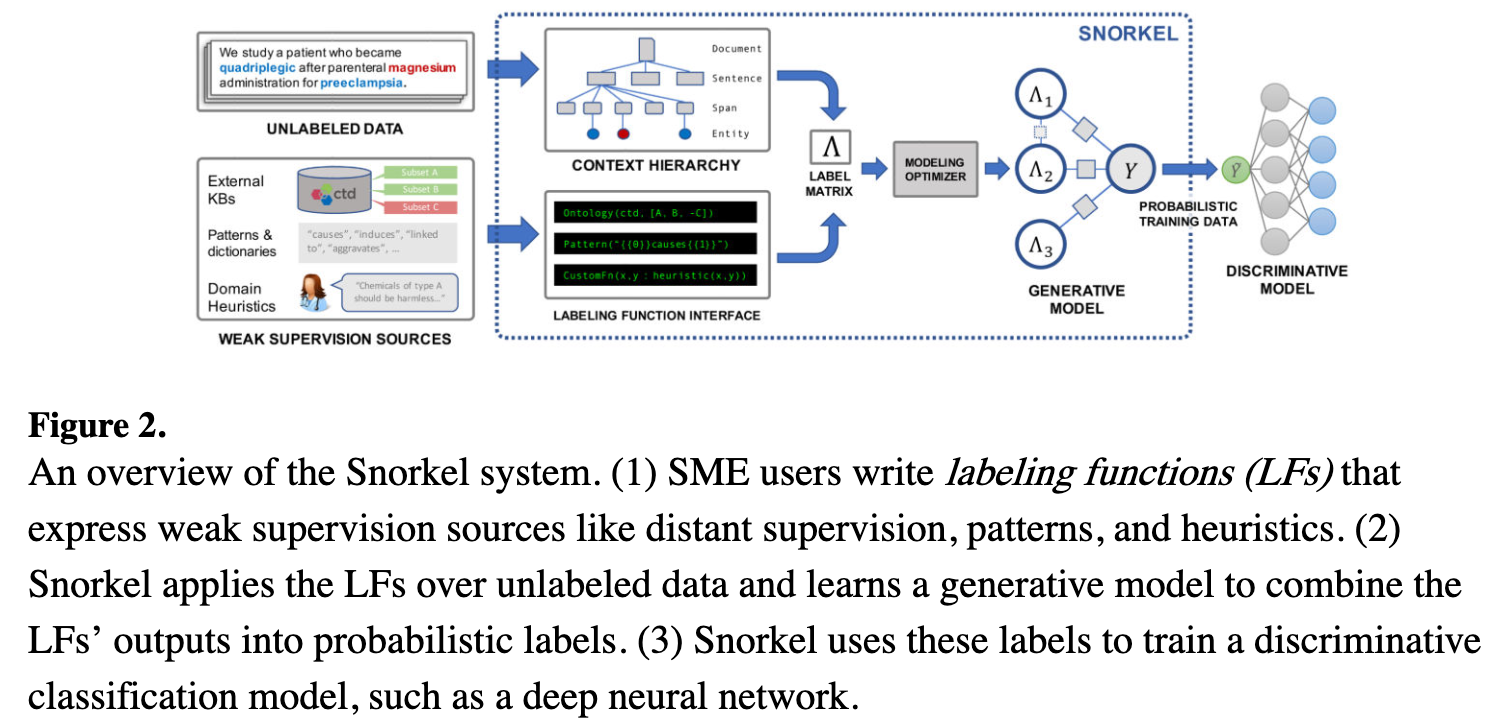
Snorkel AI continued
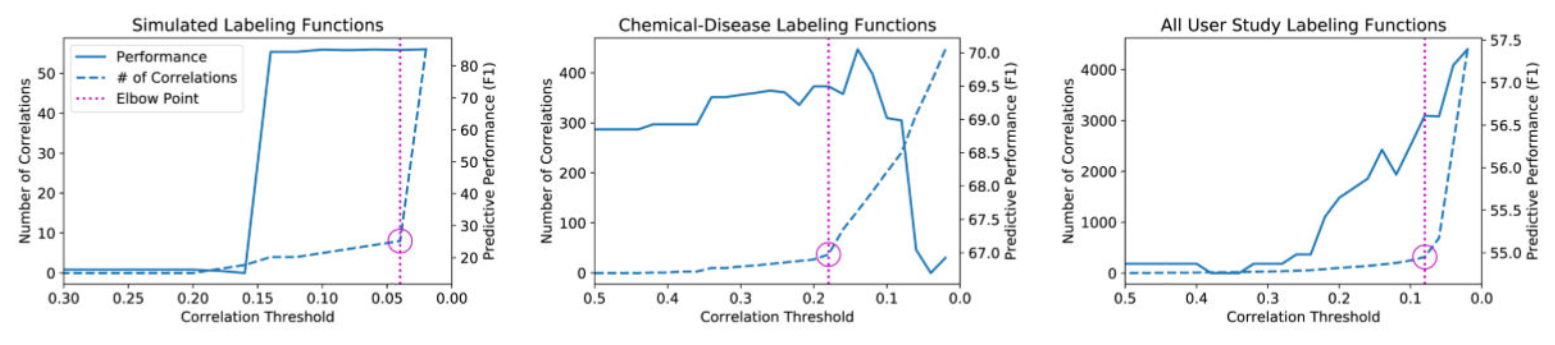
There is a trade-off space between accuracy and computational cost - How do we choose an effective modelling strategy?
Can use a heuristic that considers label density, taking expected counts of instances in which a weighted MV could flip the incorrect predictions of unweighted MV under best case - modelling advantage
Hard to define a GM that can account for modelling dependencies between labelling functions
Can use a psuedolike estimator to compute the objective gradient, requiring a threshold parameter to trade-off between predictive performance and computing cost - hit an elbow point on a graph to estimate